
Today, almost everyone has heard about Large Language Models, like ChatGPT, and since you are reading this article, you have probably tried them out. However, using them and understanding how they work are two different things. But don’t worry, many people don’t fully understand how they work.
You have probably read somewhere on the internet or in one of our articles that LLMs are trained to “predict the next word” and require a huge amount of text, like a library of books, to do this. But that is where basic knowledge often stops. The details of how they predict the next word cannot be explained simply by saying “neural networks.”
Neural networks are inherently hard to explain. In conventional programming, computers are given explicit, step-by-step instructions; however, the inner workings of a neural network can often be seen as a black box. Neural networks are trained using billions of words of ordinary language. As a result, no one on Earth fully understands the exact inner workings of LLMs, but we do have a general understanding of how these systems function.
The Short Read
A LLM or chatbot generates a given word by following a series of steps. Here’s what’s going on under the hood:
First, the input is broken up into a bunch of little pieces. These pieces are called tokens, and in the case of text, tokens tend to be words, fragments of words, or other common character combinations. If images or sound are involved, then tokens could represent small patches of the image or chunks of the sound.
Each of these tokens is then associated with a vector known as embedding,which is a list of numbers meant to encode the meaning of that piece. Words with similar meanings tend to correspond to vectors that are close to each other in a very high-dimensional space.
This sequence of vectors is then passed through an operation known as an attention block. Attention blocks allow the vectors to “communicate” with each other, passing information back and forth to update their values. After that, these vectors pass through a different kind of operation called a multilayer perceptron (MLP), sometimes called a feedforward layer. In this step, the vectors don’t interact with each other but instead go through the same operation in parallel. This is like asking a series of questions about each vector and then updating them based on the answers to those questions. For example, the numbers encoding the word bank might be changed based on the context surrounding it to somehow encode the more specific notion of a river bank.
This process essentially repeats, alternating between attention blocks and multilayer perceptron blocks. The goal is that, by the very end, the essential meaning of the input sequence has been distilled into the final vector in the sequence.
Finally, a certain operation is performed on that last vector to produce a probability distribution over all possible tokens that might come next. and then we and up with: LLM’s predict the next word.
Tokens: The Building Blocks of Text
Before a computer can process text, it must be broken down into smaller units that the machine can understand. These units are called tokens. A token can be a single word, a part of a word (subword), or even a single character, depending on the tokenization (method in which these tokens are represented) method used. In natural language processing (NLP), tokens are the basic units of text that models, such as language models (e.g., GPT-4), use to process and generate language. Tokens dictate how the model processes the text. The model doesn’t “see” the full text but rather interacts with the tokens. Each token has a unique meaning for the model, and it uses these tokens to generate responses or understand the input.
Think of tokens as the building blocks for any text the model interacts with. The process of splitting text into tokens is called tokenization.
Example of Tokenization: In this case, the model splits the sentence into 11 tokens, even though it contains 48 characters. This happens because some tokens are shorter (like “a”) or single punctuation marks (like spaces or periods) also count as tokens. Also, it is important to notice, that a token is not necessarily a word. A rule of thumb commonly used is that a token is approximately 0.75 words.
In this case, the model splits the sentence into 11 tokens, even though it contains 48 characters. This happens because some tokens are shorter (like “a”) or single punctuation marks (like spaces or periods) also count as tokens. Also, it is important to notice, that a token is not necessarily a word. A rule of thumb commonly used is that a token is approximately 0.75 words.
In another sentence: “Many words map to one token, but some don’t: indivisible.”
Here, 14 tokens are produced from 57 characters because the tokenization process breaks down longer, complex words like “indivisible” into smaller segments.
Embeddings: Converting Words into Numbers with Meaning
Human beings represent English words with a sequence of letters, like O-P-E-N for open. A language model uses a long list of numbers called a word vector. For example:
[0.0375, 0.0953, 0.0734, 0.0600, 0.0156, 0.0156, 0.0058, 0.0868, 0.0603, 0.0710, …, 0.0086]
Note that a full vector, like the list of numbers above, is typically 300 numbers long. Tokens are converted into numerical form so that a computer can process them. These large lists of numbers are called embeddings.
Language models take a similar approach: each word vector represents a point in an imaginary “word space,” where words with similar meanings are placed closer together. For example, the closest words to open include enclose, accessible, indoor, and clos. Note that clos is a token that, for a human, has no meaning on its own, but for a language model, it captures meaning likely related to closed, it is cut off due to tokenization, like we saw with indivisible above.
A key advantage of representing words with vectors of real numbers (as opposed to a string of letters, like “O-P-E-N”) is that numbers enable operations that letters don’t.

To understand how these embeddings relate to each other, let’s use an analogy involving geographical coordinates. Consider locations represented as two-dimensional vectors based on their latitude and longitude. For example, Amsterdam is located at 52.4 degrees North and 4.9 degrees East. This can be expressed in vector notation as: Amsterdam: [52.4, 4.9], Rotterdam: [51.9, 4.5], The Hague: [52.1, 4.3], Utrecht: [52.1, 5.1]. Calculating the sum of distances between two cities, we can notice Amsterdam is closer to Utrecht than to Rotterdam.
As mentioned earlier, words are too complex to represent in just two dimensions. Therefore, language models use vector spaces with hundreds or even thousands of dimensions. While the human mind cannot visualize a space with that many dimensions, computers are perfectly capable of reasoning about them and producing useful results.
Arithmetic Operations
In 2013 Google announced its word2vec project. Using millions of documents from Google News, Google analyzed which words tend to appear in similar contexts. Over time, a neural network trained to predict word co-occurrences learned to place semantically similar words (such as open and close) close together in a high-dimensional vector space. One particularly intriguing property of Google’s word vectors was their ability to support “reasoning” through vector arithmetic. For example, researchers took the vector for biggest, subtracted big, and added small. The vector closest to the resulting output was the smallest.
This ability enables vector arithmetic to capture analogies. For instance:
- Unethical is to ethical as possibly is to impossibly (opposites).
- Mouse is to mice as dollar is to dollars (plurals).
- Man is to woman as king is to queen (gender roles).
Because these word vectors are derived from how humans use language, they inherently reflect many of the biases present in human communication. For example, in some word vector models, subtracting man from doctor and adding woman results in nurse. Another example terms like top scorer might be positioned closer to man than to woman in the embedding space. This could cause a language model to favor male-associated outputs when asked questions such as, “Who is the top scorer of all time?” even when female top scorers exist.
In the example below with the table, embeddings are used to represent different roles (King, Queen, Princess, Boy) in a vector form based on their properties (such as “Royal”, “Male”, “Female”, and “Age”).
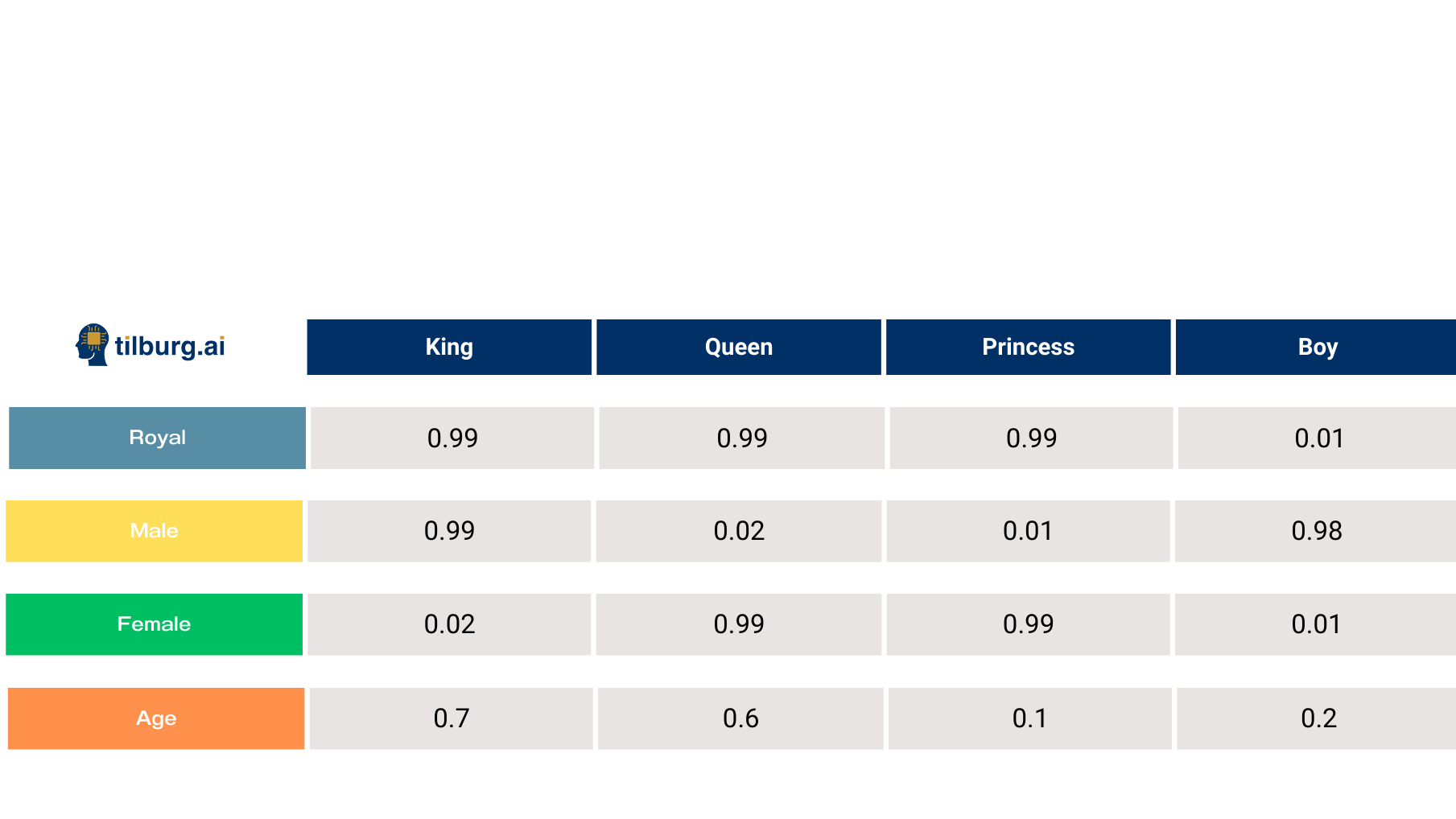
in short, word vectors, known as embeddings are a the building block for language models because they encode information about the relationships between words.
Same Word different Meaning
For example, consider the word bank, which can refer to a financial institution or the land alongside a river. Or consider the following sentences:
- Robert sat on the bank to rest after his walk.
- Sarah deposited money into her bank account.
Here, bank in the first sentence refers to the edge of a river, while in the second sentence it refers to a financial institution. These meanings are completely unrelated.
Now consider the word paper in the following sentences:
- Alex handed in his paper for the assignment.
- Emma read about the election in the morning paper.
In this case, paper refers to a written essay in the first sentence and to a printed newspaper in the second. The meanings are different but closely related—they both involve the concept of something written or printed.
When a word has two completely unrelated meanings, such as bank (riverbank vs. financial institution), linguists call these homonyms. When a word has two closely related meanings, such as paper (essay vs. newspaper), linguists refer to this as polysemy.
If we continue this line of reasoning, we naturally arrive at referents. Often, the context serves as a reference for the word, but the word itself can remain ambiguous.
For example:
- In “The teacher urged the student to do her homework,” does her refer to the teacher or to the student?
- In “The lawyer gave the witness his notes,” does his refer to the lawyer or the witness?
People resolve such ambiguities using context, but there are no simple or deterministic rules for doing so. Rather, it requires an understanding of facts about the world. For instance, you need to know that students usually do their own homework and that lawyers typically give notes to witnesses rather than the other way around.
The Transformer
GPT-3, the model behind the original version of ChatGPT, is organized into dozens of layers. Each layer takes a sequence of vectors as inputs, the prompt (question) your insert when typing in chatgpt is tokenized and then for every token we have one vector, and the layer adds information to help clarify that word’s meaning to better predict which word might come next. Let’s start by looking at a stylized example:
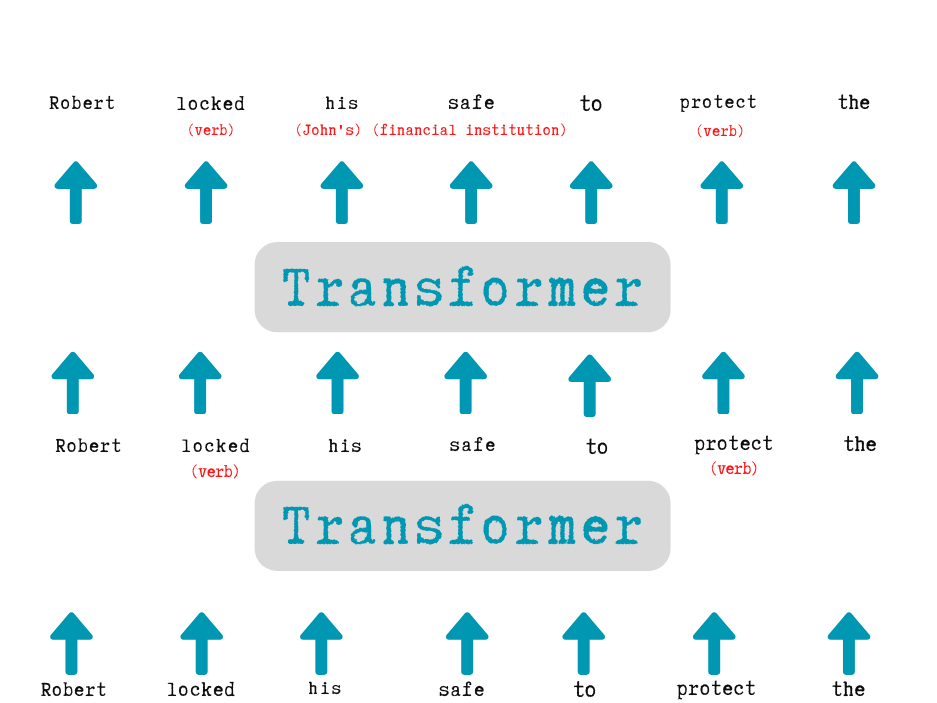
Each layer of an LLM is called a transformer, which has a neural network architecture first introduced by Google’s paper Attention is all you need. The model’s input, shown at the bottom of the diagram, is the partial sentence “Robert locked his safe to protect the.” These words, represented as embedding, list of numbers, are fed into the first transformer.
The first transformer notices potential ambiguities right away. For example, it recognizes that locked is a verb (it can sometimes be used as an adjective) and safe is likely a noun (though safe can also be used to mean “free from danger”). We’ve represented this disambiguation as red text in parentheses, though in reality, the model would store it as subtle changes to each word vector by updating the numbers in the list. These updated vectors, known as the hidden state, are then passed to the next transformer in the stack.
The second transformer adds several pieces of context: it clarifies that his refers to Robert rather than some unspecified person, and that safe here means a numeric fault and not a free of danger place. The second transformer then produces another set of hidden state vectors that capture everything the model has inferred so far.
The above figure depicts a hypothetical LLM process, so don’t take the details too literally. In real-world applications, LLMs generally have far more than two layers; GPT-3, for example, uses 96 layers. Research suggests that the earlier layers often focus on syntax, deciding how words fit together in a sentence or figuring out that locked is functioning as a verb. Later layers (not shown here, to keep the diagram manageable) often work on a higher-level understanding of the entire passage.
For instance, as an LLM “reads through” a short narrative, it appears to keep track of multiple facts about each character: their gender, motivations, relationships, and so on. If Robert needed to keep her valuables safe in one paragraph and then mention them again later, the model would somehow keep in its hidden states that “Robert is the one who owns a safe, locked it, containing valuables he wants to protect.”
Researchers don’t fully understand how LLMs encode and maintain all this information. But logically, they must do it by modifying the hidden states as words move from one layer to another. The extra “space” in modern LLMs’ massive vectors certainly helps, these high-dimensional embeddings can store nuanced context.
For example, GPT-3’s largest version uses 12,288-dimensional vectors for each token. You can think of those extra dimensions as a kind of scratch pad where GPT-3 can keep notes on whether safe refers to a vault or a concept of security.
Suppose, then, we revised our diagram above to show a 96-layer model working with a 1,000-word story. By, say, the 60th layer, the model might have a vector for Robert that includes a parenthetical note like “(main character, male, has a numeric passcode, stored valuables in a safe, likely anxious about theft).” Again, all this would be represented by a list of 12,288 numbers for Robert, or partially distributed among the embeddings for safe,, and protect.
The goal is for the model’s final (96th) layer to output a hidden state for the last word that contains all the information necessary to predict the next word accurately. Once it decides, for example, that “valuables” should be followed by a word such as “inside” or “securely,” the probabilities for those words rise compared to less-fitting alternatives, leading the model to choose one of them for its output.
In this way, the model moves beyond just counting word frequencies: it builds an internal picture of who is doing what, to whom, and why. And while humans still find it mysterious how exactly these notes and links get encoded, we know at a high level that each transformer layer adds details that help sharpen the model’s overall understanding of the text, one step closer to generating the correct next word.
Attention is all you need
Let’s zoom in a that bit further and look at what happens inside of each transformer. Here like we explained above there is an update of the hidden state, the list with list of numbers or in other words the list of embeddings for each token. The transfomre takes a two-step process for pudating the hidden stae for each of the tokens of the input prompt:
- In the attention step, words are connected with the context and share information with each other.
- In the feed-forward step, each word “thinks about” information gathered in previous attention steps and tries to predict the next word.
In the early 2010s, recurrent neural networks (RNNs) were a popular architecture for understanding natural language. RNNs process language one word at a time. After each word, the network updates its hidden state, a list of numbers that reflects its understanding of the sentence so far. RNNs worked fairly well on short sentences, but they struggled with longer sentences, to say nothing of paragraphs or longer passages. When reasoning about a long sentence, an RNN would sometimes “forget about” an important word early in the sentence. Which we saw with our referalls were essential to capture the meaning of the sentence. Who needs to be urged to do the homework? Google’s solution use an attention mechanism to scan previous words for relevant context.
The attention mechanism
The attention mechanism can be imagined as a kind of matchmaking system for words (to avoid confusion, we’ll use “words” here instead of the technically correct term “tokens”). Each word creates a checklist (a query vector) of the features it’s looking for. At the same time, each word also generates another checklist (a key vector) that describes its own features. The network then compares each key vector to each query vector (by computing a dot product) to see which words pair best. Once a match is found, the network transfers information from the word that created the key vector to the word that produced the query vector.
In the previous section, we saw how a hypothetical transformer in the sentence “Robert locked his safe to protect the…” discovers that his refers to Robert. Here’s what it might look like under the hood: the query vector for his essentially says, “I’m looking for a masculine noun that I’m related to.” The key vector for Robert then says, “I am a masculine noun.” Recognizing this similarity, the network copies information about Robert into the vector for his.
Each layer of a language model contains multiple attention heads. This means the information exchange process occurs multiple times in parallel (rather than sequentially as with RNNs). Each attention head can focus on a different task:
- One attention head maps pronouns to nouns (as described above).
- Another is concerned with the correct meaning of homonyms (e.g., bank as a financial institution vs. bank of a river).
- Yet another looks at fixed word combinations, such as “trial and error.”
- And so on.
GPT-3 as an example
GPT-3 has 96 layers, each with 96 attention heads. This means that for every next-word prediction, GPT-3 performs a total of 9,216 attention operations (96 layers × 96 heads). It is precisely this huge number of simultaneous matches and information flows that allows GPT-3 to make complex connections in text and accurately determine which words should follow.
Feed-Forward Layer
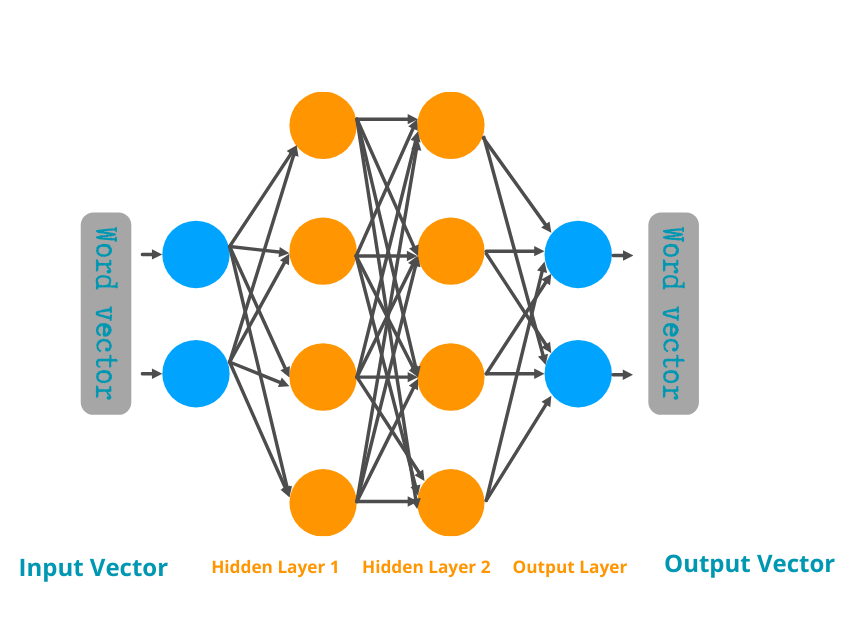
In each transformer layer, after attention has passed contextual information among tokens, the model applies a feed-forward layer(also called an MLP) like we have displayed above. Unlike attention, where words share information with each other, this step processes each word (token) individually, but in parallel. Despite only seeing one word vector at a time, a feed-forward layer can still infer the context surrounding these words as the embeddings, word vectors, have been updated by the attention heads and have already woven the surrounding context into it.
Neuron Activations: The Model’s “Thought Process”
In a neural network, a neuron is a computational unit that produces a numerical value, or “activation,” based on its input. The dots in the diagram above can be seen as neurons. Whenever an LLM processes text, certain patterns of activations, spanning thousands or even millions of neurons, enable the model to “recognize” different concepts.
A Common Issue: It’s rare for a single neuron to represent a concept on its own. Instead, each neuron may be involved in multiple concepts, and any single concept (like the “Golden Gate Bridge”) may be distributed across many neurons.
Dictionary Learning: Groups of Neurons Form Concepts
To make sense on how these neurons concepts and can be translate to be humanly interpretable, Antropic Researches have discussed dictionary learning. Rather than examining individual neurons, they focus on recurring patterns within neuron activations. These patterns are called features.
- Defining a Feature: A feature is essentially a code that the network uses to “store” certain concepts. One feature might represent the Golden Gate Bridge, while another captures something more abstract like “inner conflict.”
- Why It Matters: Highlighting these features lets us see which concepts the model is using internally (e.g., “bridges in San Francisco” or “discussions about secrets”) without getting lost in the massive array of individual neuron activations.
Feedforward Mechanism: From Features to Word Choices
After the attention step, where tokens share context with one another, the feedforward step follows. Here, the model processes each token individually, but the embeddings for each token already contain context from the earlier attention steps.
In GPT-like models or Claude Sonnet, feedforward layers (MLPs) further update each token’s representation. Thanks to dictionary learning, we know that these layers rely on features (combinations of neuron activations) to update each token’s vectors list. A feature such as “Golden Gate Bridge” becomes active when context suggests it (e.g., “San Francisco,” “iconic bridge,” or even an image). The feedforward layer then adjusts the relevant word embeddings, guiding subsequent predictions in a more accurate or consistent direction.
Claude Sonnet provides a clear example of such a Golden Gate Bridge feature. Under normal conditions, this feature becomes active whenever the input references the bridge, but dictionary learning shows that it spans multiple neurons acting together. When researchers artificially boosted this feature (“read this is the most important connection”), Claude Sonnet started identifying itself as the Golden Gate Bridge. The feedforward layers were overwhelmed by signals from these neurons, steering every response toward that topic. This shows how strongly a single feature can influence final word choices. The feedforward layers play a an key role by “fine-tuning” and “amplifying” specific concepts in the token representations.
What makes feed-forward layers so powerful is their huge number of connections (parameters). In the simple diagram, we see just a few neurons in the hidden and output layers. However, in GPT-3, each feed-forward layer is enormous:
- 12,288 neurons in the output layer (matching GPT-3’s 12,288-dimensional word embeddings)
- 49,152 neurons in the hidden layer
Each hidden-layer neuron connects to all 12,288 input dimensions, and each output-layer neuron connects to all 49,152 hidden neurons. As a result, one feed-forward layer alone can contain around 1.2 billion parameters. Because GPT-3 stacks 96 of these layers, that amounts to 116 billion feed-forward parameters—roughly two-thirds of GPT-3’s 175 billionparameters overall.
Food for thought: “The fact that manipulating these features causes corresponding changes to behavior validates that they aren’t just correlated with the presence of concepts in input text, but also causally shape the model’s behavior. In other words, the features are likely to be a faithful part of how the model internally represents the world, and how it uses these representations in its behavior” (Antrophic, 2024)
Prediction
When a feed-forward neuron recognizes its preferred pattern in a word vector, it adjusts that vector to incorporate newly inferred information. You can think of this update as adding a “tentative prediction” about what might come next. Over multiple layers, these incremental updates help the model refine its guess about the next word. By the final layer, the hidden state for each token contains enough detail for the model to produce a probability distribution over possible continuations.
In this way, feed-forward layers, working in tandem with attention, contribute to the model’s ability to disambiguate homonyms, maintain referential consistency (e.g., “his” referring to Robert), and keep context in long texts. Although we still lack a complete, fine-grained explanation for every parameter, the overall mechanism is clearer: each feed-forward step is a powerful pattern matcher that progressively refines each token’s representation, keeping the model on track to generate a sensible next word.

Conclusion
As we’ve seen, modern Large Language Models (LLMs) like GPT-3 or Claude Sonnet don’t simply “guess the next word” out of thin air. They break text into tokens, convert those tokens into high-dimensional embeddings (a long list of numbers), and use alternating attention and feed-forward layers to distill context and meaning. Along the way, concepts are represented through intricate patterns of neuron activations that researchers can uncover with techniques such as dictionary learning. These discovered “features” help explain how LLMs can recognize and generate everything from mundane objects like the Golden Gate Bridge to abstract ideas such as “inner conflict.”
Yet, we’ve also noted that neural networks often operate as a “black box”; even though we understand these broad principles, the precise internal workings remain only partially interpretable. That said, the insights we do have, tokens, embeddings, attention, feed-forward connections, and feature patterns, shed light on how LLMs infer context, disambiguate meanings, and track references acros text.
Resources
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, Ł., & Polosukhin, I. (2017). Attention is all you need. In I. Guyon, U. Von Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, & R. Garnett (Eds.), Advances in Neural Information Processing Systems (Vol. 30). Curran Associates, Inc. https://proceedings.neurips.cc/paper_files/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf

