
So far, we’ve discussed in detail on our website how to properly instruct GenAI models. Take our prompt engineering series as an example and how you can get started with GenAI as a student. It’s common knowledge that one model is considered better than another. Think about the latest reasoning models with respect to the first models around. Secondly, the prompt itself also influences the quality of the output. Today, we’ll discuss a new element: GenAI’s context window.
We will start with a general introduction to the context window. Next, we will define the context window and explore how different Large Language Models (LLMs) interpret it differently. We will examine its implications for generating output and, finally, provide practical tips for managing your context window.
What is the Context Window
The context window is the maximum amount of text, measured in tokens (words or parts of words), that an AI model can process at once. In GenAI prompts, this means that both the input (the prompt) and the output (the generated text) must fall within this limit. In simpler terms, “it is the length of the conversation added by the documents that you upload, that is remembered by the AI model. Recent research has shown that the context you provide influences the performance of the language model. The difference between a well-managed and poorly-managed context can be the difference between insightful, accurate responses and confused, inconsistent ones.
In short, a language model processes tokens, but there is a cap on the number it can handle simultaneously. This limit is known as the maximum context window.
What are tokens?
Before a computer can process text, it must be broken down into smaller units that the machine can understand. These units are called tokens. A token can be a single word, a part of a word (subword), or even a single character, depending on the tokenization (method in which these tokens are represented) method used. In natural language processing (NLP), tokens are the basic units of text that models, such as language models (e.g., GPT-4), use to process and generate language. Tokens dictate how the model processes the text. The model doesn’t “see” the full text but rather interacts with the tokens. Each token has a unique meaning for the model, and it uses these tokens to generate responses or understand the input.
Think of tokens as the building blocks for any text the model interacts with. The process of splitting text into tokens is called tokenization.
Example of Tokenization: In this case, the model splits the sentence into 11 tokens, even though it contains 48 characters. This happens because some tokens are shorter (like “a”) or single punctuation marks (like spaces or periods) also count as tokens. Also, it is important to notice, that a token is not necessarily a word. A rule of thumb commonly used is that a token is approximately 0.75 words.
In this case, the model splits the sentence into 11 tokens, even though it contains 48 characters. This happens because some tokens are shorter (like “a”) or single punctuation marks (like spaces or periods) also count as tokens. Also, it is important to notice, that a token is not necessarily a word. A rule of thumb commonly used is that a token is approximately 0.75 words.

The growth of context windows in Large Language Models (LLMs) is nothing short of impressive. While GPT-3.5 Turbo could only process 16,000 tokens, modern models such as ChatGPT-4o can now process up to 128,000 tokens (approximately 96,000 words) of information simultaneously. Even more recently, the leap has been to more advanced reasoning models that can process up to 200,000 tokens, with 100,000 output tokens. Some models, such as Gemini Flash 2.0, even offer context windows of 1 million tokens, enough to handle entire books. For comparison, the three volumes of The Lord of the Rings together contain over 480,000 words, which equates to approximately 640,000 tokens.
Okay, great? “We get bigger context windows, I can put books in them, and I still get a more precise answer.” But here’s the premise: Just because an AI can process more text doesn’t mean it will process it well. In fact, research consistently shows that performance on complex tasks actually declines as context length increases.
Research on the Context Window
Recent research has shown that the performance of AI models (consistently across different models) deteriorates as context length increases. This is a statement we need to dissect, if that’s the case, why have context windows continued to grow?
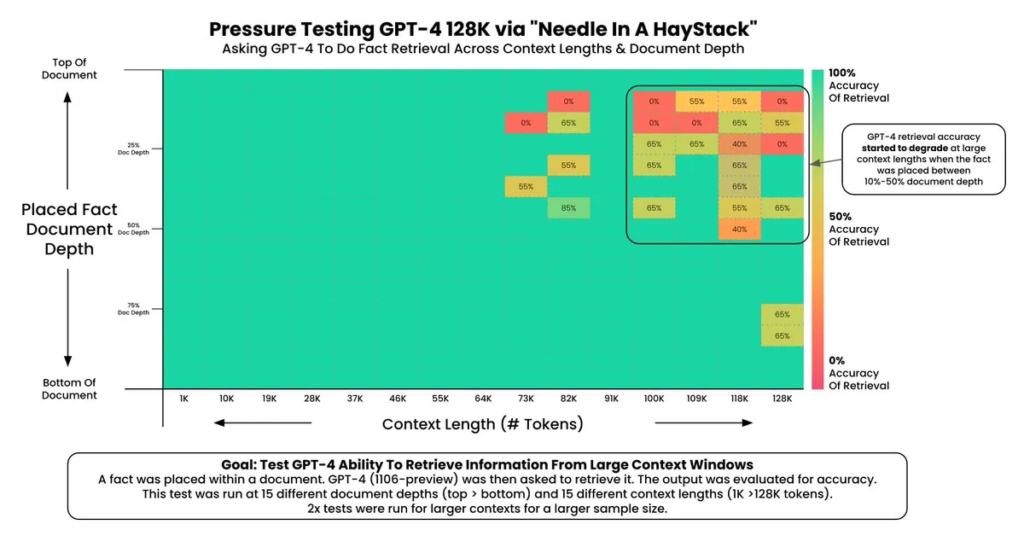
Needle-in-a-Haystack Test
A key factor driving this trend is the “needle-in-a-haystack (NIAH)” test, where a specific piece of information (the “needle”) is embedded within a lengthy block of text (the “haystack”) to assess the model’s ability to retrieve it. Modern AI models are now nearing perfect performance in this task, which has been a key driver behind the expansion of context windows.
However, this success raises a question: how does this generalize to most day-to-day cases? Many of these benchmarks involve tasks where the input query (e.g., a question or instruction) contains literal matches to the provided context. Do such literal matches make it easier for language models to locate relevant information and generate correct answers? In other words, do these benchmarks allow models to exploit direct matches between the “needle” and the “haystack,” thereby reducing the task’s complexity?
NOLIMA Test
Recent research has introduced a new framework, NOLIMA, designed to evaluate the reasoning capabilities of large language models (LLMs) in long contexts, and is intended to be significantly more challenging for LLMs than the traditional NIAH benchmark. Unlike NIAH, which often involves literal matches between the prompt and the relevant information (“needle”), NOLIMA minimizes this literal overlap. This means that this benchmark must rely on associative reasoning capabilities rather than superficial matching, thereby better testing the true capabilities of the models in long context understanding.
Okay, let’s break the previous paragraph down. Normally, when you ask a question in NIAH about a long text, the LLM can search for words that match the question. But NOLIMA makes that harder: by not showing any clear similarities between the question and the answer. The question and the answer (the “needle”) have almost no words in common. The LLM has to make the connections itself. In addition, the language model sometimes has to take a few steps to find the answer (associative reasoning). For example, if the question is “Which character has been to Dresden?” and the text says “Yuki lives next to the Semper Opera House”, the LLM has to know that the Semper Opera House is in Dresden to know Yuki has been in Dresden.
Several factors contribute to the complexity of the NOLIMA benchmark. The context length itself is a key challenge, as the performance of LLMs decreases significantly as the context length increases, even for models that claim to support long contexts. The ordering of information also plays a role, with inverted examples being harder to answer. Furthermore, the presence of literal matches can negatively impact results, even if they are irrelevant. Distracting words that overlap with the query can confuse the models and reduce performance. The position of the needle in the context can also have an impact, with a so-called “lost-in-the-middle” effect in longer contexts.

What Does This Mean In Practice
In practice, this means that while modern LLMs excel at finding the needle in the haystack, they struggle with tasks that require connecting ideas across different parts of a document.
This includes:
- Connecting indirect lexical meanings (such as the link between an opera and the city it is located in).
- Maintaining consistent reasoning across long output.
- Forgetting boundary conditions mentioned earlier in the conversation.
- Mixing up details from different versions of a document being worked on.
- Getting stuck in repetitive patterns that require a fresh start to break.
The NOLIMA benchmark shows that LLMs often rely on superficial similarities between the question and the context, which can lead to distractions and irrelevant answers. Even Chain-of-Thought (CoT) prompting doesn’t completely solve these challenges, because the difficulty often lies in the association between the question and the information needed, rather than in the complexity of the reasoning itself. For simple factual queries, this might not matter. But for creative writing, complex problem-solving, or nuanced analysis, it can impact the quality of the response.
How LLMs Differ in Managing Your Conversations
Before we explore specific solutions or methods for handling large contexts, it’s important to first understand that each model, Anthropic's Claude, OpenAI's ChatGPT, and Google's Gemini, interprets, retains, and processes conversational context in different ways. In other words, different LLMs remember past conversations differently and doffer how they use the knowledge in subsequent interactions.
1. Claude (Anthropic)
- Full-context retention: Stores every exchange (user + AI responses) until the token limit is reached.
- Strengths: Maintains coherence and continuity throughout conversations, doesn’t make a separation of what has been said earlier or later in the conversation..
- Trade-off: Context window limits are reached faster. Once full, the entire conversation history is truncated.
2. ChatGPT (OpenAI) | Gemini Flash (Google)
- Rolling window approach: Prioritizes recent messages while gradually phasing out older ones.
- Key nuance: Truncation happens invisibly, your chat history remains visually intact, but the model only “sees” the most recent tokens.
- Trade-off: Long conversations may lose thematic continuity as early context disappears from memory.
3 Tips for Context Window Management
Below we have created a list of tips to resolve the context window flooding.
- Start a new conversation
Although convenient, it is wise to start a new conversation regularly. As discussed above, an LLM has to sift through the entire conversation history to find relevant information. This can slow down performance and cause the model to become “distracted.” In a new conversation, you can start with only the information you need by copying and pasting it from the previous conversation.
Break down subtasks while writing a paper. For example, in chat #1, work on brainstorming the idea or creating a structure outline. Then start a new conversation for each chapter and paste the relevant parts from the previous conversations into the new conversation.
Tip: Use summaries as connectors, if beginning anew, request the AI to recap key points from your prior conversation to use into the new conversation.
2. Re-edit Prompts
Instead of focusing on the amount of context, like starting a new chat every time, you can also manage the quality of the context window. You can do this by replacing irrelevant prompts with new ones. In short, if you are not satisfied with the answer, hover over your prompt, click the pencil, and edit your prompt. This means that your context stays focused because you are modifying the original instructions.

This is specifically relevant for those working with Claude. Since Claude has a certain limit on the size of the context, it is important to keep it relevant.
3. Use Placeholders to Tag Information
Placeholders are explicit markers (e.g., <key_term>, <critical>, or custom tags like !!NOTE!!) that highlight specific details in long contexts. These act as bookmarks for the LLM, making it easier to reference information even in large context windows.
Why this works:
- Guides attention: Models like Claude or ChatGPT prioritize text wrapped in tags, similar to how bold/italic text emphasizes human readers.
- Reduces “lost-in-the-middle” effects: Details buried in long texts are easier to retrieve when flagged with placeholders.
Best practices:
- Use consistent tags (e.g.,
<definition>,<warning>,<step>) to create predictable patterns. - Limit tags to critical info only overuse dilutes their impact.
- Combine with summaries: Start a new conversation and paste tagged snippets from prior chats to retain focus.
Want to learn more about these placeholders, check out our specific article about it here.
Conclusion
Quantity does not equal quality: larger context windows do not automatically lead to better answers. In this article, we have shown that handling the context window is of importance for the quality of an AI models answer. At the same time, we have shown how LLMs deal with the proverbial needle in the haystack. Therefore, practical management, especially for longer conversations, is important. This can be done by regularly starting new conversations, going back in a conversation, and using a more precise, focused prompt. You can also use placeholder techniques to steer the AI’s attention.
Source Paper: https://arxiv.org/abs/2502.05167.

