

What if creating a real-life film clip was as easy as typing a few sentences? OpenAI has introduced Sora, which we define as, breathtaking. Sora is a generative video model that turns this possibility into reality. Sora transforms sentences, prompts, into detailed video clips. Meaning that the video production process has been simplified immensely.
We always say a picture is worth a thousand words, let alone a video. So, we invite you to be the judge. This video was created by Sora with the following prompt: “The camera directly faces colorful buildings in Burano, Italy. An adorable Dalmatian looks through a window on a building on the ground floor. Many people are walking and cycling along the canal streets in front of the buildings.“
If you have become eager to uncover the mechanics behind this “magic,” then you’ve come to the right place. This article delves into the fascinating world of Sora. It will explore Sora, the possibilities it opens up, the risks it carries, a dive into the inner workings, and the hurdles for the future to overcome.
Exploring Sora
At its essence, Sora is an AI tool designed to bridge the gap between imagination and reality by transforming text prompts into dynamic and visually real life videos. It’s like being able to simply type out your ideas and watch as Sora brings them to life on screen. But Sora’s capabilities extend further than this so-called text-to-video translation.
Beyond text prompts, Sora can handle various input formats, including images and pre-existing videos. This flexibility enables users to explore a even wider range of possibilities:
- Animating Static Images: Sora has the ability to produce videos when given an image and a prompt as input.
- Connecting videos: Sora can be used to create a smooth transition between two input videos, gradually blending them together to create “seamless” transitions even when the videos feature entirely different subjects and scene compositions.
- Existing Video Editing: Sora can edit images and videos from text prompts and is able to transform the styles and environments of input videos.
- Extending Video Duration: Sora is also capable of extending videos, either forward or backward in time. This feature allows users to adjust the duration of videos as needed.
One other feature of Sora is its emergent simulation capabilities, this means it can mimic real-world aspects like how people, animals, and environments behave, all without being directly taught (read coded). This means Sora has the following abilities:
- 3D Consistency: Sora makes videos where the camera moves around, like zooming in or panning across a scene, and keeps everything looking right in 3D space. Imagine a video where the camera circles around a dancer, and despite the movement, the dancer’s motions remain fluid and natural from every angle.
- Long-Range Coherence and Object Permanence: It’s keeps track of what’s happening over time. For example, if a dog runs out of the frame and comes back later, Sora remembers and keeps the dog looking the same. This is like when you’re watching a movie, and a character leaves a scene but looks the same when they return.
- Interacting with the World: Sora can show simple interactions realistically. Think of a scene where someone is painting; you’d see the paint actually getting applied to the canvas over time. Or if someone eats a piece of pizza, you’d see the slice getting smaller with each bite.
However, the current model has its limitations. It might not always get the physics of a scene right or fully grasp how certain actions lead to specific outcomes. For instance, if someone takes a bite out of a cookie, the model might not show the cookie with a bite mark missing. It can also mix up details in the scene, like confusing which side is left or right, and might have trouble accurately following events over time or sticking to a specific path the camera is supposed to take. OpenAI also mentions that the model doesn’t fully grasp cause and effect, leading to unexpected or unrealistic outcomes.
Is Sora Available to use?
Access to Sora is currently restricted to a limited group of researchers and video creators, a precautionary step taken to ensure compliance with regulatory standards and ethical considerations. OpenAI has positioned the release of Sora as a preview of future capabilities, while there are no immediate plans for broad public release. OpenAI states it is collaborating with third-party safety evaluators, as well as a curated group of creators and artists, to refine Sora’s functionality and address potential safety and ethical concerns.
Risks Associated with Sora
The company says it is working with experts in misinformation, hateful content, and bias to test the model and build tools to detect misleading content. Similar to its Dall-E software, Sora is designed with strict limitations to prevent the creation of content that includes violence, sexual content, hateful images, or uses intellectual property without authorization. Sora also conducts frame-by-frame video analysis to ensure compliance with the safety standards. Additionally, Sora enhances security by incorporating fake-image detection technology, first introduced in DALL-E 3. At last, it integrates so-called C2PA tags in all outputs, providing metadata to signify that the content is AI-generated.
Copyright concerns: The importance of addressing copyright concerns is highlighted by a lawsuit filed by The New York Times against OpenAI in the previous year, accusing the company of extensive copyright infringement in the process of training its AI models, especially DALL-E. This case stresses the legal and ethical challenges for the tech industry to use large datasets for AI development, spotlighting the ongoing debate over intellectual property rights.
A Dive into the Inner Workings of Sora
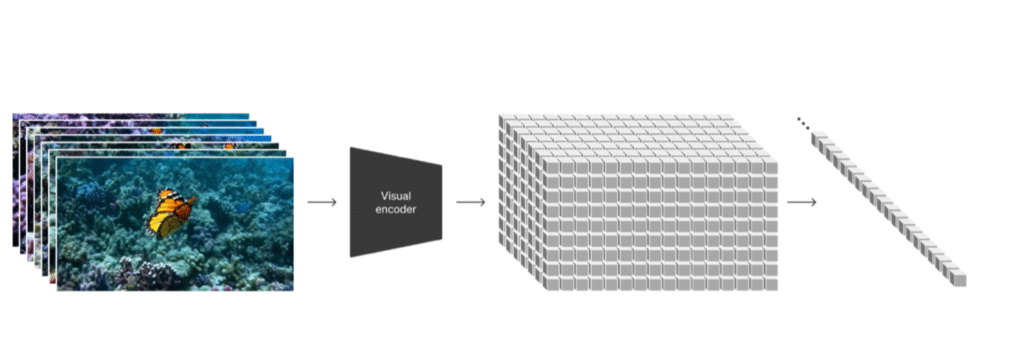
Imagine if we could teach computers to understand and create videos as easily as we write sentences. That’s precisely what Sora does by using a trick inspired by how we read and write text. Just as words are the building blocks of sentences, Sora uses “visual patches” as the basic units for videos and images. Let’s break this down into simpler terms to understand how Sora works.
The Idea of Visual Patches
Think of a visual patch like a puzzle piece in a much larger picture. When you’re trying to solve a puzzle, you look at each piece to figure out where it fits in the overall image. Sora does something similar with videos. It breaks them down into small pieces (patches) that it can easily analyze and understand. This method allows Sora to handle all sorts of videos, from short clips to longer sequences, in various qualities and formats.
The transformation process starts with compressing the video, similar to packing a suitcase before a trip. You want to fit everything you need (the essence of the video) into a smaller space (a so called lower-dimensional latent space) so it’s easier to carry around. After packing, Sora cuts the video into smaller chunks, much like slicing a cake into pieces so everyone can have a portion. These slices are the spacetime patches, and by cutting both across space (the image) and time (the video duration), Sora can focus on each piece one at a time.
Videos aren’t naturally easy for AI to understand because, unlike text, they’re continuous streams of information without clear breaks. It’s like trying to read a book with no spaces between words, it would be challenging to figure out where one word ends and another begins. By slicing videos into patches, Sora creates those necessary “spaces,” making it easier for the AI to process. This is like how we humans use spaces and punctuation in writing to make text readable.
Diffusion Model
Building on the concept of “visual patches” as fundamental units for understanding and creating videos, Sora uses a technique inspired by the DALL-E 3 model. This technique, known as a diffusion model, is similar to an artist turning a canvas of random noise into a detailed picture. Let’s delve deeper into how Sora fills in these visual patches to transform text descriptions into videos, maintaining the analogy and terminology introduced earlier.
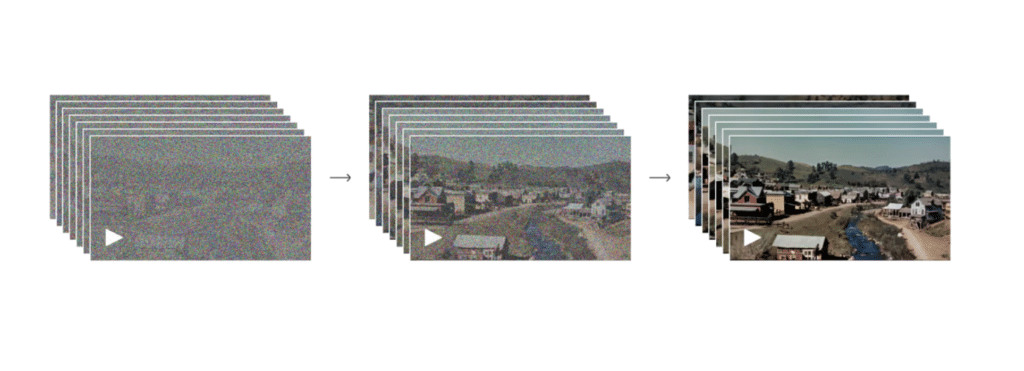
What is diffusion? Imagine diffusion as the natural process of perfume slowly spreading through a room, moving from a concentrated area to evenly fill the entire space. This visual helps us grasp how diffusion models tackle complexity, starting from a simple base (random noise) to achieve a rich, detailed outcome. In the realm of machine learning, this principle guides the transformation of basic data into complex, structured outputs, much like how dispersed perfume molecules eventually perfume an entire room.
The Process of Filling in Visual Patches:
- Data Preprocessing: The process begins with organizing and standardizing the input data, think of this analogy: preparing a canvas for painting. This step ensures the model works from a common starting point.
- Forward Diffusion (Adding Complexity): The model takes a simple starting point, like a random noise pattern, think of a TV screen that is not working and showing black and white pixels, and starts the process of ‘diffusion.’ Step by step, it introduces slight changes, adding layers of complexity like an artist adding rough outlines, then fills in details, colors, and textures. In the context of transforming text into video, Sora takes the initial prompt and begins to generate video frames, each starting as random noise and progressively becoming a detailed scene that captures the essence of the text.
- Training the Model: The model learns how to transform this noisy (TV screen) into detailed outputs by being trained on a huge set of examples. The training phase fine-tunes the model’s ability to generate realistic images or videos.
- Reverse Diffusion (Creating New Images or Videos): With its training complete, the model can reverse the diffusion process. It starts with noise and systematically adds detail to create a new, non-existent image or video. For Sora, this means slowly rendering video frames that are not only visually appealing but also contextually aligned with the initial text description.
Note: This article simplifies the complex technology behind OpenAI’s Sora, making the revolutionary AI video creation tool understandable for everyone. We’ve brought to light the essence of Sora’s capabilities and innovations into an accessible overview, ensuring readers can grasp how it’s changing the video production landscape without getting lost in technical jargon.
Sora’s Hurdles to Overcome
Despite the impressive nature of the sample videos, which were likely cherry picked to highlight Sora’s capabilities optimally, it’s challenging to assess how illustrative these examples are of the model’s standard output. However, there are some limitations that are likely still not fully solved within Sora:
- Handling Dynamic Scenes:
- Why It’s Hard: Dynamic scenes involve elements that constantly change positions, interact unpredictively, or alter the scene’s composition. Capturing and predicting these changes requires understanding and anticipation of physical laws and interactions within a digital environment.
- Example: Consider a scene where a ball is thrown off-screen and then caught when it comes back. Predicting its trajectory, speed, and the exact moment it re-enters requires complex modeling of physics and motion that Sora might struggle with.
- Understanding Complex Storylines:
- Why It’s Hard: Videos often tell stories or convey messages through a sequence of scenes, requiring a deep understanding of context, symbolism, and narrative structure. Sora needs to comprehend not just individual frames but how they connect to form coherent stories.
- Computational Resources:
- High-quality video generation demands substantial computational power and memory, especially for processing and generating long or complex videos.
Conclusion
In wrapping up our exploration of OpenAI’s Sora, it’s clear that this technology is set to revolutionize the way we create and perceive video content. By turning simple sentences into real-life video clips, Sora not only simplifies the video production process but also opens the door to limitless creative possibilities. It embodies the “magic” of transforming the abstract into the concrete, making the act of video creation as simple and intuitive as jotting down a note.