Lecturer’s FAQ: Artificial Intelligence in Education
Q: What is Tilburg University’s policy on using AI in education?
A: The general attitude of the Executive Board and the Vice-Deans of Education is that AI is here to stay, and we need to adapt to it.
To help guide educators in this process, here are five rules of thumb from learn.tilburg.ai:
- Set Aside Face-to-Face Time to Discuss Academic Integrity with Students
Schedule dedicated time to discuss academic integrity and the responsible use of AI tools with your students.
- Teach and Assess Higher-Order Thinking Skills
Focus on teaching and assessing skills like critical thinking, problem-solving, and creativity. These higher-order skills are valuable because they go beyond what AI can easily replicate and foster deeper understanding and analytical abilities in students.
- Evaluate Fraud Risk on the Course Level
AI usage policies should be set at the course level.
- Run Assignment Instructions Through AI Yourself
Before assigning tasks, run the assignment instructions through AI tools like ChatGPT to see what types of responses might be generated. This practice helps anticipate how students might use AI.
- Don’t Rely on Detection Tools
Avoid over-reliance on AI detection tools, as they can be unreliable.
Q: Is my input used to train models?
A: Yes.
When you use AI models like ChatGPT, the inputs you provide, such as text, file uploads, and feedback, can be used to train and improve these models. Below are statements from OpenAI explaining how your data is utilized:
“Our large language models are trained on a broad corpus of text that includes publicly available content, licensed content, and content generated by human reviewers. We don’t use data for selling our services, advertising, or building profiles of people, we use data to make our models more helpful for people. ChatGPT, for instance, improves by further training on the conversations people have with it, unless you choose to disable training.” [Source]
"As noted above, we use Content [(i.e., input, file uploads, or feedback)] you provide us to improve our Services, for example to train the models that power our Services.” [Source: OpenAI's EU Privacy Policy]
Sub-Q: How can I protect my privacy with ChatGPT?
Privacy Management Tips:
- Use A Temporary Chat
Use the temporary chat feature to prevent your input in a single session with ChatGPT from being used as training data.
Temporary chats are deleted from systems within 30 days but are still reviewed to monitor for abuse. However, they won’t be used for model training. Existing conversations, on the other hand, will still be saved and may be used for model training unless you have opted out.
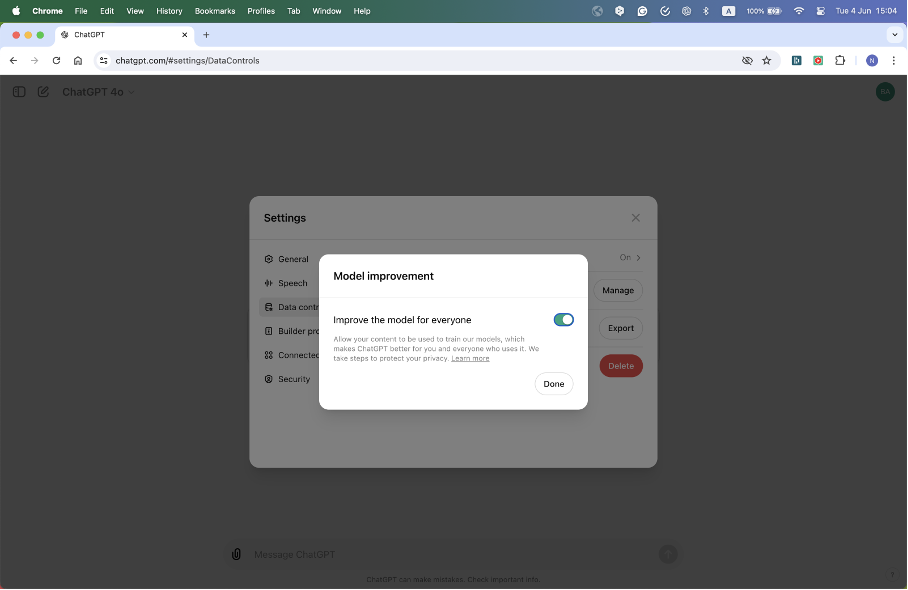
2. Opt Out from Data Usage for Training for All Chats
OpenAI allows users to opt out of having their data used for training across all chats. You can disable the usage of your inputs for training on different platforms by following the steps below:
- Web Interface (Logged Out User):
- Step 1: Click on your profile icon at the top-right corner of the page.
- Step 2: Select Settings from the menu.
- Step 3: Navigate to Data Controls.
- Step 4: Disable the option “Improve the model for everyone.”
- iOS App:
- Step 1: Tap the three dots in the top right corner of the screen.
- Step 2: Select Settings from the dropdown menu.
- Step 3: Go to Data Controls.
- Step 4: Toggle off the option “Improve the model for everyone.”
- Android App:
- Step 1: Open the menu by tapping the three horizontal lines in the top left corner of the screen.
- Step 2: Select Settings.
- Step 3: Go to Data Controls.
- Step 4: Toggle off “Improve the model for everyone.”
When this setting is turned off, the conversation will still appear in your history (on the left-hand side of the screen). But the conversation will not be used for training.
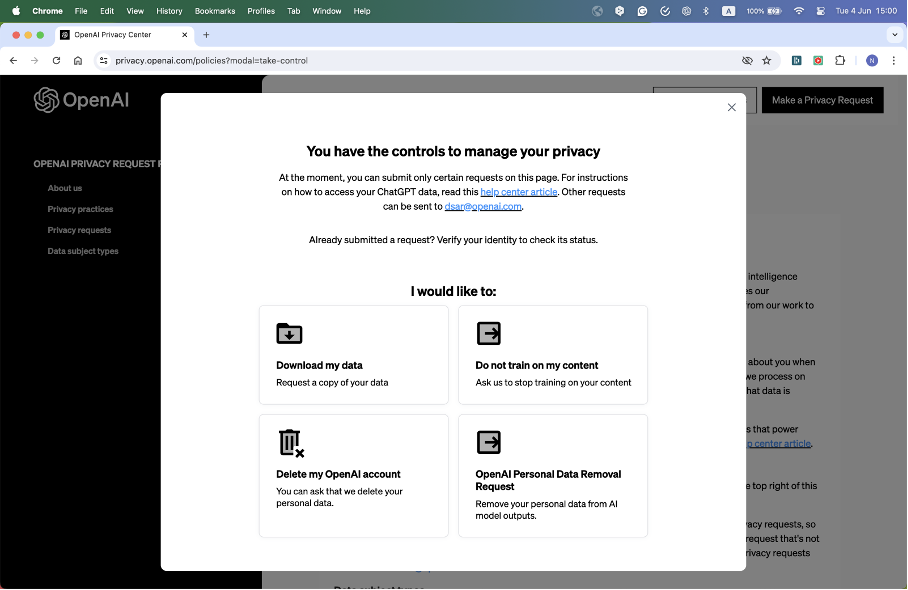
3. Request Deletion of Personal Data from Model Output
If personal data appears in outputs after some time, you can request to have this data deleted from the model’s outputs.
Step-by-Step:
- Step 1: Visit the OpenAI Privacy page.
- Step 2: Locate the section on Data Removal Requests.
- Step 3: Follow the provided instructions to submit a request to have specific personal data removed.
- Step 4: Provide necessary details of the data to be deleted, if required.
- Step 5: Submit your request and await a response from OpenAI confirming the deletion process.
Q: Is it fair for me as a lecturer to use AI to create course materials and assessments, and ban students from using it in the same course?
A: Could be.
The use of AI tools like ChatGPT in academia raises questions of ethics. Here are some opening considerations:
- Transparency
Transparency is a cornerstone of ethical behavior in academia. If you use ChatGPT to create assignments, it may be fair and ethical to disclose this to your students. Being transparent can help build trust, foster a culture of honesty, and set a positive example for students. - Fairness
One of the reasons for prohibiting students from using ChatGPT is that you want to make sure they engage in critical thinking and learning processes. If you as a lecturer use the tool without disclosure, it might create a perception of a double standard. However, the context of use differs: while you use ChatGPT to create balanced and challenging assignments, students might use it to bypass learning. The purpose behind each use is key to understanding its fairness. - Purpose and Context
Consider the purpose behind your rules and use of ChatGPT. If the primary goal is to help students develop specific skills and understanding, reflect on whether your use of ChatGPT aligns with that objective. For instance, using ChatGPT to generate high-quality, fair, and comprehensive assignments that accurately evaluate student learning could be justified.
Q: What if my students refuse to use LLMs?
A: No problem.
Currently, the use of Large Language Models (LLMs) like ChatGPT should not be mandatory for students. Students should have the choice to opt-out if they are uncomfortable or have concerns. It’s important to respect their preferences.
Q: Were copyrighted materials used to train the models?
A: (Probably) Yes.
Copyright-protected material is likely used in training AI models. Below, you will find several sources that provide further explanation on this topic:
- For a starting understanding of this topic, you may refer to the article titled OpenAI says it’s impossible to create useful AI models without copyrighted material” (Ars Technica).
Below is a summary, along with additional sources:
- Necessity of Copyrighted Material: OpenAI argues that using copyrighted material is essential for developing AI models like ChatGPT. Nearly all forms of human expression, from blog posts to software code, are copyrighted. Excluding these materials would mean that AI models would be trained only on very outdated and limited datasets.
- OpenAI’s Submission to the UK’s House of Lords, Read the full submission here.
"Because copyright today covers virtually every sort of human expression, including blog posts, photographs, forum posts, scraps of software code, and government documents, it would be impossible to train today’s leading AI models without using copyrighted materials. Limiting training data to public domain books and drawings created more than a century ago might yield an interesting experiment, but would not provide AI systems that meet the needs of today’s citizens.”
- Tradition in Machine Learning: Historically, OpenAI states that using data from the internet has been a standard practice in academic research on machine learning. arguing that while this practice stayed under the radar when it was purely academic, it is now under heavy scrutiny because AI models have become commercial.
- Read more in OpenAI’s open letter: OpenAI and Journalism.
"Training AI models using publicly available internet materials is fair use, as supported by long-standing and widely accepted precedents. We view this principle as fair to creators, necessary for innovators, and critical for US competitiveness.”
- Legal Context and Fair Use: OpenAI defends its position by claiming that using publicly available internet content is covered under the “fair use” doctrine. They argue that this principle is essential for fostering innovation and that restricting such data would significantly hinder both innovation and the practical application of AI.
- Read more: OpenAI’s Blog Post on Fair Use.
- Fair Use Justification: OpenAI argues that training AI models with publicly available internet materials is supported by long-standing legal precedents of fair use.
- Legal Challenges: OpenAI faces ongoing legal disputes, such as the lawsuit from The New York Times, challenging the application of fair use in AI training, but OpenAI argues these claims overlook the established limitations and exceptions within copyright law.
Q: Are LLMs bad for the environment?
A: Currently, yes.
- Efficiency of LLMs Compared to Specialized Technologies. Large Language Models (LLMs) like GPT-4 are general-purpose technologies designed to perform a wide range of tasks, from answering questions to generating text. However, when an LLM is used for specific tasks, such as web search, it tends to be less efficient than specialized technologies. For example, traditional web search engines are optimized specifically for searching, making them faster and more efficient than LLMs for this particular task.
- Carbon Footprint of LLMs.There has been significant concern about the carbon footprint of LLMs, which refers to the total greenhouse gas emissions associated with their training and operation. Initial estimates of this footprint, such as those by Strubell in 2019, were quite pessimistic and generated alarming headlines. However, newer estimates, such as those discussed in a recent study by Faiz (2024), provide a more accurate and nuanced view of the environmental impact. Read the full paper here.
- Variability in LLM Carbon Footprints. The carbon footprint of LLMs can vary significantly depending on several factors
- Model Size: The largest and most advanced LLMs, designed to outperform competitors, are highly carbon-intensive. The difference in energy consumption between large and smaller, more efficient LLMs can be drastic, potentially by a factor of 100. However, there is also a push to create efficient “small” LLMs, even ones that could run on your own computer.
- Energy Source: The environmental impact also depends heavily on the cleanliness of the energy powering the data centers where these models run. Clean, renewable energy sources can drastically reduce the carbon footprint, much like the difference in carbon emissions between taking a flight versus a train.
Just like the decision between taking a flight or a train can lead to vastly different carbon footprints, understanding and considering these “multipliers” is crucial when evaluating LLM usage.
- Transparency and Responsible Use: Not all LLM developers are transparent about their models’ environmental impact. For example, the developers of GPT-4 have not disclosed detailed information about the carbon footprint of their models. It is recommended to use LLMs that provide clear and specific data on their environmental impact to avoid incentivizing non-transparent and potentially harmful practices.
I would recommend only using LLMs that make clear numerical statements about their carbon footprint. We must not incentivise bad practice. (Dan Stowell, CSAI – TiU, May 2024)