

Why (very) smart systems can have (very) dumb goals
Recently, Geoffrey Hinton, aka the “Godfather of AI”, estimated that there is a 1 in 10 chance of AI causing catastrophic consequences within the next 5-20 years. Think of human extinction-level events.
While not everyone in the AI field agrees with the likelihood and time frame, there is an increasing number of people who express their concern about risks posed by advanced AI systems. Grace et al. released a survey in January 2024 that gathered responses from 2,778 researchers who had published in top-tier AI journals. Between 38% and 51% of the respondents believed there is at least a 10% chance that advanced AI could lead to outcomes as bad as human extinction.
There are several ways in which these gloomy future scenarios might pan out. The first one that comes to mind is that human actors will abuse future AI systems to catastrophic consequences. But what if we told you that there is another reason why advanced AI systems can become incredibly dangerous, even if we deploy them with the best of intentions? This has to do with the nature of intelligence itself and, most notably, with the immense challenges of creating safe intelligent systems.
AI Safety in a Nutshell
In simple terms, AI safety is about ensuring that as AI systems become more capable and autonomous, they remain aligned with human values and do not pose unacceptable risks. Imagine a world where intelligent machines make decisions that unintentionally harm people or society. AI safety aims to prevent such scenarios by designing AI systems that are reliable, transparent, and accountable. In discussing AI safety, it’s important to differentiate it from AI security. While AI security primarily concerns regulating and safeguarding AI systems from malicious attacks or human misuse, AI safety focuses on preventing AI systems from causing harm through their own actions or decisions. Deepfakes are for example a concern in AI security rather than AI safety.
Where things go wrong in current AI systems
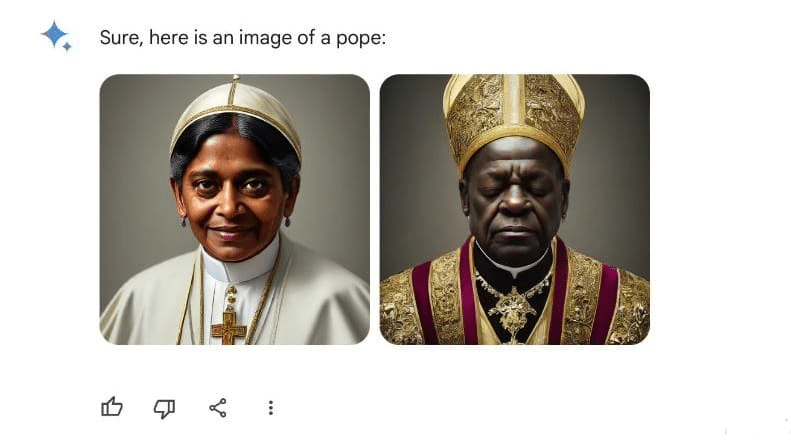
There are plenty of examples where AI models can miss the mark in surprising ways. Take, for instance, the case of Google Gemini which created AI images of historical figures that showed a black pope or Asian-looking German soldiers during World War II. The issue for this problem lies in Google’s goals for Gemini, which aims to achieve equal representation of race and gender. But in this case, this led to unrealistic portrayals. Another example is the agent trained by OpenAI in the game CoastRunners, which is a boat race game. If humans play this game, their aim is typically to win the boat race, i.e., to finish ahead of other players. In CoastRunners, an OpenAI-trained agent, using reinforcement learning (RL), was aimed to win the boat race by maximizing its game score. Instead of racing, it found a loophole in the game by repeatedly crashing into a wall and collecting power-ups; it could earn more points than when finishing laps. Both instances are examples of a lack of alignment where an AI finds a way to fulfill its goals in undesirable ways.
Lack of Alignment Versus Lack of Capabilities
Note that in both examples above, the model is perfectly capable of doing what we would expect it to do (i.e., create images of people with the historically accurate race and gender or actually complete the laps in the race). However, during training, the models learned that they could satisfy the specified goals even better by deviating from the “correct” behavior. Both instances are examples of the alignment problem. Systems that are misaligned will still optimize for goals they were originally trained on. However, their eventual learned behavior neglects or conflicts with other criteria that are either desirable or even required but were “forgotten” by the researchers. To put it differently, misaligned systems have incomplete goal definitions. This gap between the goals they should have and what they actually have can then lead to unintended side effects (USEs). USEs like the two shown above are well-known “argh”-moments for AI researchers where they find out that your AI model technically does what it’s supposed to but does so in a way that completely defeats the purpose. So, clearly, when designing AI systems, aligning them to one’s actual and complete goals is at least as important as making sure they are capable of fulfilling these goals.
The implicit assumption here is that we could all agree on whether an AI is doing “the right thing” once we deploy it in a realistic test scenario (unless the model is actively deceiving us, but we will get to that in a minute.) This, of course, ignores the fact that different people will have different views on correct and desirable behavior, especially when the model’s decisions might influence people’s lives or other things they care about. This issue is a separate can of worms that deserves its own article(s). For the purpose of this article, however, let’s keep things simple. We will assume that every human in the world shares the same set of general goals and values, and could discern actions that work towards them versus that work against them (categorical imperative-style).
Aligning AI Systems with Human Feedback
Alignment already plays a crucial role in our most advanced AIs to date. It turns out that when ChatGPT-3.5 was released in November 2022 and instantly got viral, it probably was not even the smartest model we had at the time. In fact, its predecessor, GPT-3, which is rumored to even have many more parameters, was already able to do most of the things that made ChatGPT-3.5 an instant hit. However, if you pitch the two models against each other, you will see that GPT-3 has a strong tendency to “misbehave”. When you give it a prompt, it sees the text that it needs to “complete” and continues generating text that aligns with what it has seen during training. This means GPT-3 rarely answers direct questions. To actually get the output you are looking for, you will need to prompt it in rather clumsy ways. ChatGPT-3.5, on the other hand, has no trouble understanding that you asked it a question, and it will happily answer it.
So rather than releasing a more powerful-than-ever AI model, OpenAI achieved their breakthrough by aligning existing technology to a much greater extent. They did so by applying and massively scaling up a technique called Reinforcement Learning from Human Feedback (RLHF). RLHF is a way to incorporate human judgment when fine-tuning a model towards a certain desirable behavior. For this, human evaluators are asked to rate the quality of a model’s responses over and over again. If done enough times, the AI ends up responding much more in a way that is useful for a typical user. Put differently, chatGPT-3.5 is much better aligned to the human way of working than GPT-3. For a more in-depth explanation of RLHF you can check out our earlier article on the concept.
Dumb Systems are Safe systems
By now you might already have an idea of why and how misaligned AI systems might behave in undesirable ways. But before we discuss why misaligned systems could actually be dangerous, let us take a moment to reiterate why our most advanced AI systems follow goals in the first place. We are simplifying a lot here, but when training an AI, researchers always have to come up with a so-called reward function. For the AIs we discussed so far, this could be
- “Maximize the score in the bottom left of the screen”
- “Reproduce existing pictures as accurately as possible based on a text description”
- “Reproduce an existing piece of text as accurately as possible based on the first paragraph”
Note that the reward functions are not exactly the goals we actually want, but rather proxies for them. But regardless of how well we translated our goals into one or more reward functions, the AI will then religiously stick to them and try to optimize its behavior to get the highest reward it can.
How well the AI will learn to obtain the highest reward depends on many factors that we can simplify and compound to the “capabilities” or “intelligence” of the system. An AI playing the game might get very good at optimizing the score, even when it, in a general sense, is significantly less capable than, for example, ChatGPT. But even if an AI is really good at one thing, we can imagine that it would probably get much better at that if we would expand its capabilities and its circle of influence. For example, we could give it the ability to see and rewrite the game’s code. Then, nothing would keep it from finding even more exploits, such as simply having the game start with the maximum score. While such solutions would probably not be useful to the AI researcher, they would probably be a much more efficient way to maximize the reward function, as they skip the whole learning process of playing the game. And if it’s more efficient, it is better, right?
At the end of the day, “dumb” AIs such as ones that can only play video games can never become unsafe. The main reason for this is that they simply lack the capabilities to become dangerous. They can’t take actions in the real world as they are limited to a small virtual environment and they have no way of knowing anything else. Aligning such an AI is still important, as we have seen before. But it is also typically quite easy, because we can measure and understand all relevant metrics (such as the game score) beforehand, and even if the AI misbehaves (like crashing into a wall to keep collecting power-ups) it is easy to spot, adjust the reward function and try again.
Smart(er) Systems and Do you actually know what you want?
So how smart does a system have to be before it can cause harm in the real world? Surprisingly, it turns out not very smart. In fact, we already have AI systems that can and probably do harm due to a lack of alignment. Take, for example, content recommendation systems that work in the background to make a selection for your newsfeed on platforms like Facebook, X, YouTube, or Instagram. Since these platforms rely on ad revenue, the companies behind them have a vested interest in users spending as much time as possible on their platforms. In terms of training a recommendation AI, this (combined with other metrics like clicks or other user engagement) offers a straightforward way to construct a reward function. The longer users spend on the site and the more they engage, the better. From a commercial standpoint such a reward function might sound very reasonable, and companies want to maximize profit after all.
However, now we potentially have an AI system, that presents content to millions and maybe even billions of people worldwide with the sole goal of user spending time on the platform. If the algorithm is well-designed, it might learn to push our buttons better and on a much larger scale than human curators ever could. Before we know it, this can lead to unforeseen changes in the word’s media landscape. Research has shown that fake news is often received more favorably than true reports (Vosoughi et al., 2018), while Tintarev et al. (2024) found that news recommendation engines can by themselves influence public opinion. Since fair media coverage and the truthfulness people’s beliefs play such a crucial role in democratic systems, there is serious concern that news recommendation systems could cause unforeseen harm worldwide (Helberger, 2019).
So why would the engineers and decision makers at those companies not consider the broader implications of their design choices? Don’t they also profit from political stability, both financially but also for their overall quality of lives as well? Why it is absolutely possible, that these considerations were made, we would argue that most of the time people simply didn’t think of them. Or maybe they did but they didn’t feel like their system would actually become so good at what it’s doing that it could cause problems. Either way, we can argue that, even from the point of view of the interests of social media companies, recommendation systems can easily become misaligned with the companies’ actual and complete goals
This tells us about a very common property if AI systems, which is their tendency to focus solely on their given goals and don’t automatically detect or regard the implications for other aspects in their circle of influence. If we forget to specify something that we care about, the AI will happily sacrifice that aspect in exchange for even very small improvements towards its goals.
A system that is optimizing for a function of n variables, where the objective depends on a subject of size k<n, will often set the unconstrained variables to extreme values. If one of those unconstrained variables is something we care about, the solution found may be highly undesirable.
Stuart Russell
What about (very) smart Systems?
It should be clear by now that the smarter and more capable our AI systems become, the more important it is to make sure they actually behave in the way we want them to and that they don’t cause unintended side effects (i.e. harm). The more we move from decently smart systems like recommendation engines and chatbots to more powerful systems, that understand and can act within the real world, the more critical alignment becomes. We don’t know if and when, but several companies such as OpenAI openly state that their long-term goal is to come up with so-called Artificial General Intelligence (AGI) that achieves or even surpasses human level intelligence in all domains.
For more insights into what AGI is and the milestones it may soon reach, check out our article “When Will AI Become Smarter Than Humans?“.
As systems become better at understanding the real world, they also get better at understanding humans as an important actor within it. In fact, ChatGPT already passes the famous Sally-Anne test that is used to test for social cognitive abilities and a valid theory of mind. It will even pass the test in an alternate version that it did not see in its training data.

While this might sound like good news for aligning AI to our needs and wishes, there is also another, darker side of the coin. As AIs get better at understanding us, they will also get better at deceiving us. Why an AI would deceive us even if we didn’t explicitly give it the goal to do so might seem counterintuitive at first. But remember, during training the AI will try to learn any behavior that satisfies its reward function in an efficient way. So, imagine a capable system that finds a shortcut to maximize its reward, just like in the CoastRunners example. But this time the AI is actually so smart that it anticipates that we might not like that shortcut at all and that we would want to shut it down, change its source code and try again. Foreseeing this, the AI would conclude that in that scenario, it would get zero reward. The AI might then decide that it would be the best course of action to explore different ways to satisfy the reward function. But it might also come to the conclusion to go for the shortcut anyway… but pretend it took another round and deceive us about its true intentions. While all of this might sound like speculation, there are already documented cases where AIs were dishonest to humans to achieve their goals.
To remedy this, we could of course try to punish the AI for dishonesty with a suitable (negative) reward function. But how would we define dishonesty in terms of numbers? Can we even come up with a foolproof definition? And once we think we have found a good definition of dishonesty, will we be able to prove that we thought of all eventualities? Remember, we might be dealing with a system that is smarter than us and can thus “outsmart” us easily after we deployed it.
There comes a point where [a superintelligent AI] becomes extremely dangerous. And that point is as soon as you switch it on.
Robert Miles in Deadly Truth of General AI?
Where are we now with AI safety?
As mentioned earlier, goals that are defined by humans are often incomplete or outright “dumb” and dangerous. RLHF on the other hand has proven to be an effective way to align our current, most advanced AI systems. RLHF or a variant of it could probably also be used to train much smarter systems, including potential future AGI. It elegantly avoids the problem that we don’t know and cannot formulate exactly what humans want and value. Instead, we use the subjective human “feeling” side of things by repeatedly letting human evaluators decide if the AI in training is showing desirable behavior. That way, the model has to implicitly learn a reward function first, so it can predict what humans would want while at the same time learning how to behave this way. This, however, obscures the goals the AI learns from our oversight and prevents us from double-checking them. But even if we do find a way to train AI with a verifiable and human-centered reward function, we still couldn’t ensure the system might not go rouge in unforeseeable ways. This is because it is incredibly hard to come up with a comprehensive list of human values and things we care about. This is made even harder by the fact that a superintelligent AI could come up with incredibly creative solutions to our most pressing problems, which could lead to novel scenarios and edge cases that we would have never thought of ourselves.
Not only might more capable systems cause more harm when misaligned, aligning them should be expected to be more difficult than aligning current AI.
Dung in Current cases of AI misalignment and their implications for future risks
So, we would need an AI that explains its reasoning faithfully to us and then leave the final decision on what to do to us. But as we have seen before, honesty is just as hard to define in a bullet-proof way and currently we have no way of knowing if we did a good enough job. So, if somebody would invent superhuman AI tomorrow, we might easily end up with a (very) smart system with (very) dumb goals that could lead to no less than human extinction.
As we have seen, however, as long as AIs are dumb enough, there will be inherently safe. In fact, some actors in the AI field argue that we are nowhere near AGI, so there is no need to worry about safety at this point. Yann LeCun, chief scientist at Meta, for example, argues that it will take at least several decades for AI systems to rival human-level intelligence.
Human-level AI is not just around the corner. This is going to take a long time. And it’s going to require new scientific breakthroughs that we don’t know of yet
Yann LeCun in ElPais
However, this sentiment is shared only by a minority of AI researchers. Grace et al. found that in 2023 a whopping 70% of the researchers who had published in top-tier AI journal believe that we should prioritize AI safety research more or much more than now. And a short but concise letter stating the existential risk of AI published by the Center for AI safety has been signed by countless AI researchers and other notable figures.
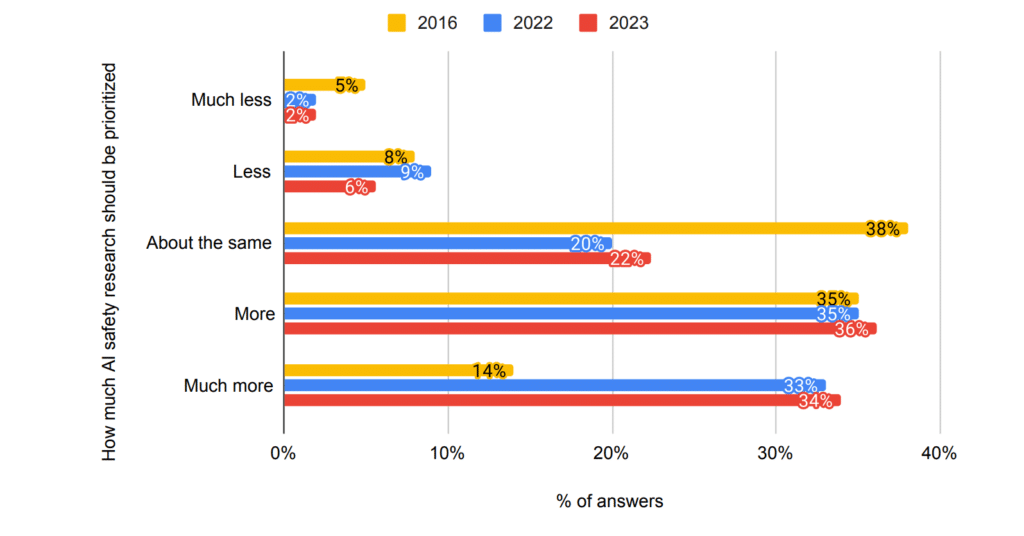
Adapted from Grace et al. (2003), Thousands of AI Authors on the Future of AI. arXiv:2401.02843 [cs.CY]
Used under the CC BY 4.0 license
Statement on AI Risk published by the Center for AI Safety:
“Mitigating the risk of extinction from AI should be a global priority alongside other societal-scale risks such as pandemics and nuclear war.
We can see that the attention for AI safety is growing among non-experts and slowly expanding into the mainstream public discourse. Among other public figures who are expressing their concerns is King Charles III, who recently published a public address on the matter. And while the recently accepted EU AI Act does not talk about AI alignment specifically, considerations for safety do play a significant role.
What is alignment research, anyway?
AI Safety is […] a [really] hard problem in the sense that a problem can be quite hard, and you can look at it and you can tell it’s quite hard. A problem that is really hard is a problem that when you look at it and you immediately think you have a solution, but you don’t. AI Safety is that really hard problem.
Robert Miles
A popular way to study AI alignment is to build transparent and simplified test systems. Just as car manufacturers test new cars under controlled conditions before selling them, AI developers use these simplified environments to safely explore and understand how AI behaves. These test environments are designed to be less complex and easier to control than the real world, which helps prevent accidents and mistakes. This way, researchers can see how the AI reacts to different situations, make necessary adjustments, and ensure it works well without causing harm. This step is important for identifying potential safety issues and fine-tuning AI operations before they are deployed in more complex, real-world situations.
The challenge of aligning AI is not solely a technical one. It likely requires no less than to really understand what humans care about in the most fundamental and universal sense possible. This is why an interdisciplinary effort is needed, combining knowledge and skills from different fields or areas of study, such as computer science, social sciences, behavioral studies, economics, humanities and philosophy. For instance, OpenAI actively seeks social scientists to better understand human goals. With the rapid innovation with AI capabilities, AI research should advance at least as fast (and ideally significantly faster) in AI alignment to ensure the technology remains safe.
The elephant in the room here is the question if it even possible to make safe AGI (Artificial General Intelligence) in the first place. As of now, the only way to ensure that would be by means of a mathematically sound fundamental proof. Otherwise, there might always be uncertainties about whether we did a good enough job of specifying everything we care about so that the AI is truly safe.
If you want to learn more, check out the excellent resource AISafety.info. For example, you can read more on why and how AIs might act in dishonest ways or why we can’t just put a “stop button” on it.
Conclusion
AI safety and specifically AI safety is a crucial piece of the puzzle towards ever smarter and powerful AI systems. For most people it feels counterintuitive why it is so important and at the same time so difficult to get right. Hopefully though we made it clear in this article that it is not science fiction and that it is a real problem that a majority of AI researchers are concerned about. Ensuring AI systems are aligned and safe requires more than just a technology-focused perspective. The topic tackles some of the most fundamental questions of what we value and what makes us human and thus requires a combined effort from many fields of research. While we do not know when we will get to systems that are powerful enough to pose existential threat, making AI safe gets increasingly important the smarter our AI systems become. If you want to get involved yourself, this article is a good point to start.
Sources
Thanks goes to Robert Miles, whose work and especially his amazing YouTube channel gave us the inspiration to write this article.
- Miles, R. Intro to AI Safety, Remastered [Video]. (2023, February 10) https://www.youtube.com/watch?v=pYXy-A4siMw
- Thornhill, J., How fatalistic should we be on AI? Financial Times, (2024). https://www.ft.com/content/c64592ac-a62f-4e8e-b99b-08c869c83f4b
- Grace, K. et al., Thousands of AI Authors on the Future of AI. (2024) arXiv:2401.02843 [cs.CY]
- Vosoughi, S. et al., The spread of true and false news online. Science 359,1146-1151(2018). https://doi.com/10.1126/science.aap9559
- Tintarev, N. et al., Measuring the benefit of increased transparency and control in news recommendation, AI Magazine. (2024), https://doi.org/10.1002/aaai.12171
- Helberger, N. On the Democratic Role of News Recommenders. Digital Journalism, 7(8), 993–1012 (2019). https://doi.org/10.1080/21670811.2019.1623700
- Dung, L. Current cases of AI misalignment and their implications for future risks. Synthese 202, 138 (2023). https://doi.org/10.1007/s11229-023-04367-0
- AISafety.info

