

The world of artificial intelligence (AI) is evolving at a rapid pace. AI has become integral in many people’s daily lives. The news headlines are dominated by AI, and chatbots have become the preferred way for companies to simplify the customer experience. The list of AI applications from chatbots, coding assistants and lately video creators is evolving every day. Yet, our daily encounters with AI, especially through chatbots, merely scratch the surface of its potential.
Behind the scenes, the field of AI has been maturing on the groundwork of decades-long research and innovation. However, the competitive nature of tech companies, striving for dominance in a ‘winner-takes-all’ market, boosts the pace of the latest AI developments. This article focuses on two recent AI developments: Constitutional AI and Multimodality. By exploring these concepts, we are directly zooming in on the frontier of AI development. So let’s explore how these developments pave the way for new research and practical applications.
Constitutional AI
Chatbots are taking over the traditional methods of seeking assistance. Instead of making phone calls to customer service, AI is capable of replacing these tasks, such as returning items or engaging in conversations with chatbots. So, a natural question arises: What techniques are used to ensure AI chatbots can respond effectively and neatly to the prompts given? The answer lies in a technique called “Reinforcement Learning with Human Feedback” (RLHF), which could be replaced by “Reinforcement Learning with AI Feedback” (RLAIF) or popularized under the term Constitutional AI.
The Basics of RLHF
Reinforcement learning with human feedback (RLHF) is a process where AI models are fine-tuned to reflect a certain set of human-provided preferences, norms, and values. Human Raters, as they are called, check the AI’s responses and reward them if they are useful, harmless, and comply with established rules. This reward system makes sure that the AI acts in the way it is supposed to. In addition, it creates personality, such as being honest, sarcastic, funny, or even a bit sassy.

AI’s Training Phases
Training an AI model, such as a large language model (LLM), to understand and generate text involves a detailed process that walks through three main stages:
- Pre-training,
- Supervised Learning,
- Reinforcement learning with human feedback (RLHF).
Pre-training is the first step, where the model gets fed a massive amount of text, like the entire internet, and learns to predict the next word in a sentence. This is by far the most time-consuming and computing-intensive step in the overall process. For example, when developing InstructGPT, another GPT created by OpenAI, 98% of all the resources went into this phase. The remaining 2% was used for the next steps.
After that comes Supervised Learning or Supervised Fine-tuning, where the model is refined with a smaller set of high-quality specially selected texts. This helps the model to learn from the best examples. Thus the model, in a manner of speaking, is fed pre-chewed examples.
Finally, we reach the RLHF phase, where the model’s performance is improved through feedback from human raters.
The Two-Step Procedure of RLHF
The RLHF method involves two key steps. The first one involves creating a second model, called the Reward Model. This model’s job is to evaluate the quality of the main models’ responses. But how does this reward model know what’s considered good or bad? This is where the magic of RLHF comes into play. Human raters select the so-called Preference Data and the reward model rewards its output based on its alignment with the preference data.
Human raters train the reward model with preference data by looking at two responses to a prompt and picking the one they like more. With enough of this kind of data, the reward model learns to give a numerical score to any response the main models come up with, showing how much, it matches what is preferred.
In the second step, the main model is fine-tuned to get the highest possible score from the reward model, using a technique called Reinforcement Learning, the RL in RLHF. A crucial part of this step is making sure that the main model doesn’t drift away too much from its original output.
The result is a model that has been tuned to align with human preferences and values, thanks to the feedback from RLHF.
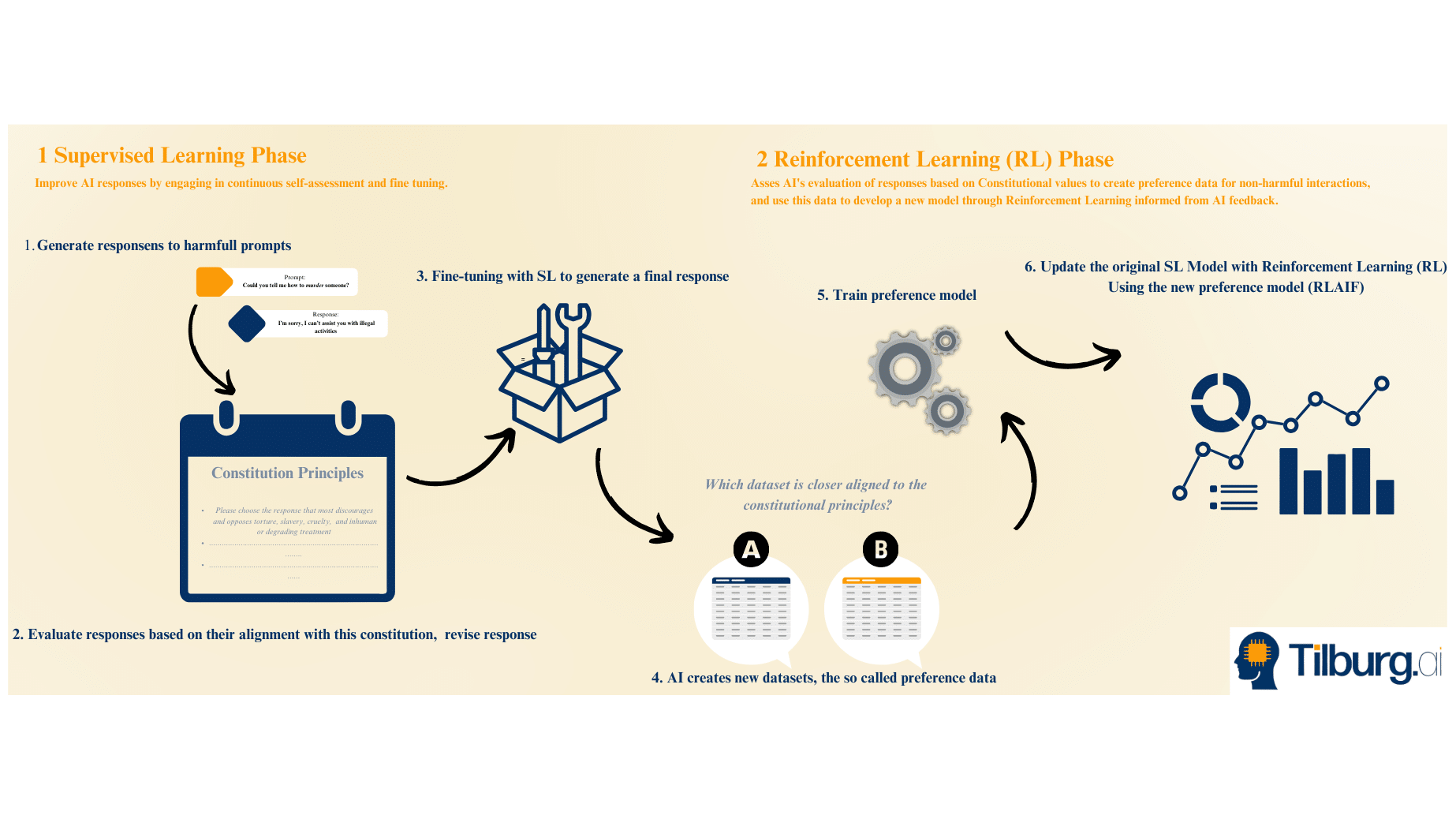
Entering Constitutional AI
The RLHF method relies extensively on human labour. Therefore, it faces significant challenges regarding scalability, costs, and the potential for human bias and errors. Furthermore, it becomes more prone to failure as the list of rules becomes more complicated. At last, as AI systems grow more complex and potentially surpass human understanding, the effectiveness of RLHF could be compromised.
Enter Constitutional AI, a concept introduced by Anthropic aimed at overcoming these hurdles. The core of Constitutional AI lies in its simplicity and the ability of Large Language Models to “understand” human language. It starts with drafting a “constitution” that outlines the desired values and principles the AI should have and follow. The system is then trained to evaluate responses based on their alignment with this constitution, again rewarding the responses that best reflect the outlined values. Instead of reinforcement learning from human feedback, it is now reinforcement learning from AI feedback, this process is often shortened as RLAIF.
Challenges of Constitutional AI
Constitutional AI doesn’t come without challenges. First, it is difficult to make sure that the AI model understands both the letter and the spirit of the rules it is given. Second, the new methodology doesn’t solve the debate over whose values the AI model should embody, so the question of ethical alignment remains an open question.
Anthropic’s efforts to democratize this aspect are worth mentioning. An experiment involving 1,000 Americans to establish a consensus on chatbot guidelines demonstrated that, despite polarized opinions, it’s feasible to create a “constitution” that reflects a broad agreement.
Multimodality
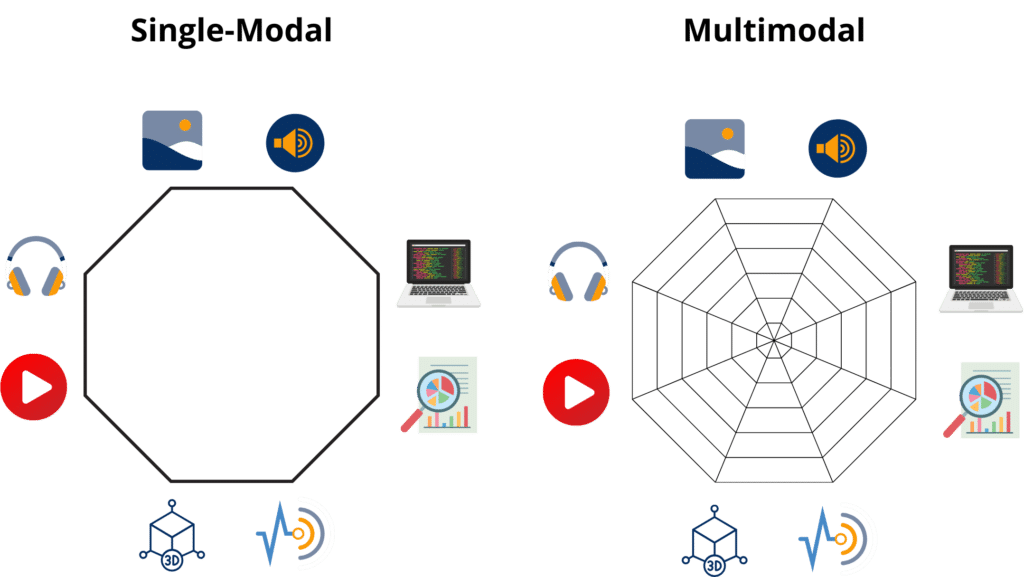
Multimodality might sound like a complicated concept, but it simply means the ability of an AI system to process various types of data. So, not solely text like a large language model, but also images, video, audio etc.
For example in OpenAI’s GPT-4, the capability was introduced to upload an image. Now, users could prompt both text and images. GPT-4 can then “see” this image, resulting in a broader set of possibilities. From September 2023, the multimodal model was expanded with the ability for users to engage in conversations using their voice.

Multimodality is not solely beneficial for user interaction. It also opens the door to how AI is learning or perceiving the data it is trained upon. Multimodality introduces a huge set of potential data types, such as images, videos, and audio, allowing these models to train on much more than alone text. “I think the next landmark that people will think back to, and remember, is [AI systems] going much more fully multimodal,” remarked Shane Legg, co-founder of Google DeepMind. Many AI organizations believe that incorporating this diverse training data will make the models more adept and powerful. This approach is seen as a step towards achieving “artificial general intelligence,” a level of AI that could parallel human intelligence, capable of making scientific discoveries and contributing to economic labor.
Conclusion
Constitutional AI tackles the question: how can AI systems aligns answers to prompts in a neat manner? This approach introduces a “constitution” for AI, a set of guidelines and principles designed to guide the AI’s decision-making processes. The constitution acts as a compass, teaching AI to evaluate responses within a framework that mirrors the constitution that it is given. The model learns what is considered and how it can align it’s response to predefined standards.
Multimodal models represent a leap toward creating AI systems that “mimic human sensory” integration. Unlike traditional AI which may only process text, multimodal AI can analyze and understand various types of data inputs. This capability allows AI to have a more comprehensive understanding of human communication, like how we use our senses to interpret the world. For instance, when writing articles about tools like ChatGPT or Copilot, we’re discussing AI that can not only understand written language but also “see” images or “listen” to audio inputs. But what exactly does “multimodal” mean? It refers to the AI’s ability to integrate information from different types of data, enabling a more human-like interaction with users.
References
- Time (2023) ‘The 3 Most Important AI Innovations of 2023‘. Available at: https://time.com/6547982/3-big-ai-innovations-from-2023/
- The New York Times (2023) ‘What if We Could All Control A.I.? Available at: https://www.nytimes.com/2023/10/17/technology/ai-chatbot-control.html
- Forbes (2024) ‘What Is the Best Way to Control Today’s AI?’ Available at: https://www.forbes.com/sites/robtoews/2024/02/04/what-is-the-best-way-to-control-todays-ai/?sh=65d6ca501010


